overleaf template galleryLaTeX templates — Recent
LaTeX templates for journal articles, academic papers, CVs and résumés, presentations, and more.

LaTeX template for preparing an article for submission to the Journal of Samara State Technical University, Ser. Physical and Mathematical Sciences (Russian Template) This LaTeX template (v1.03, 02 Aug 2021, lite version) can be used to prepare a research article or a short article (letter) in Russian for submission to the Journal of Samara State Technical University, Ser. Physical and Mathematical Sciences. Once your article is complete, you may submit it to MSS (the Manuscript Submitting System) via this link . More information on the Journal of Samara State Technical University, Ser. Physical and Mathematical Sciences can be found in this site .

A beamer template for use at University of Copenhagen following the UCPH design guide at https://designguide.ku.dk/ For any suggestions, problems or bug fixes, please contact imf@math.ku.dk

En beamerskabelon til brug på Københavns Universitet efter KU's designguide på https://designguide.ku.dk/ For forslag til ændringer, problemer eller fejlrettelser bedes du kontakte imf@math.ku.dk
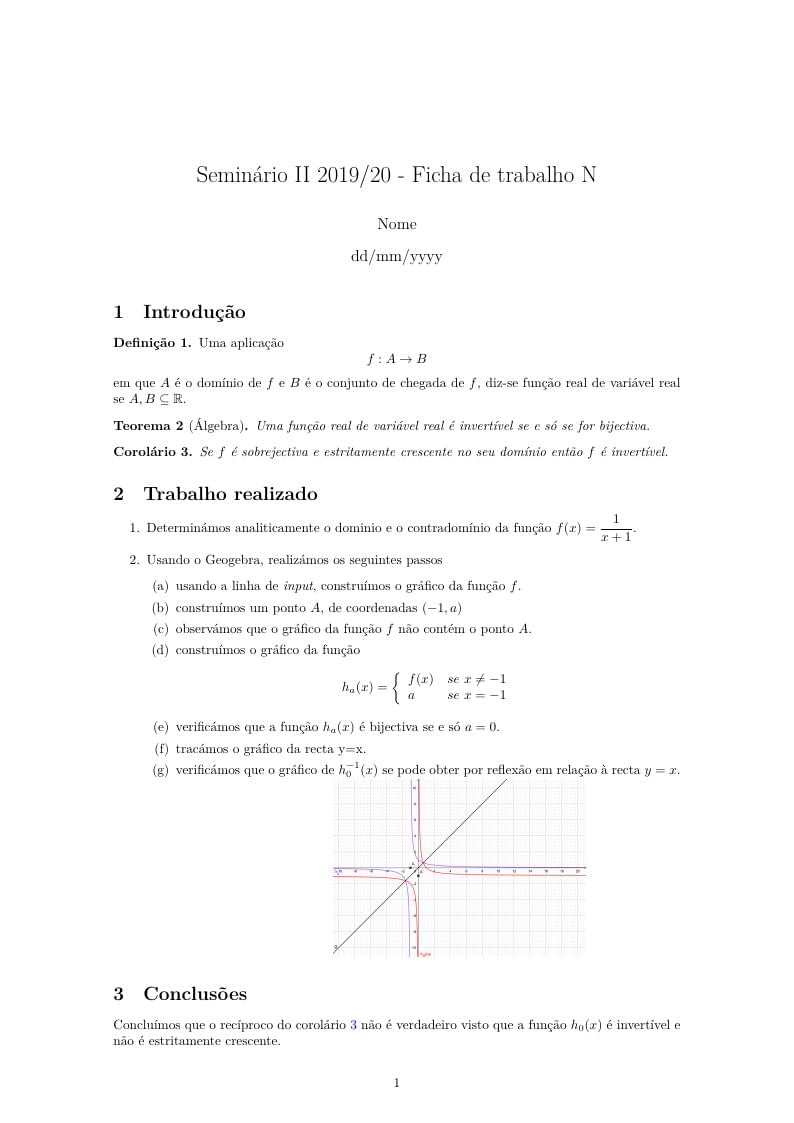
Ficheiro para registar os resultados das experiências realizadas na disciplina Seminário II - módulo funções em 2019/20

A thesis and project template for use at University of Copenhagen following the UCPH design guide at https://designguide.ku.dk/ For any suggestions, problems or bug fixes, please contact imf@math.ku.dk

Guideline doctoral plan department of Computer Science ETH Zurich

Minimalistic manuscript template (for scientific publication)

The preparation of these files was supported by Schlumberger Palo Alto Research, AT&T Bell Laboratories, and Morgan Kaufmann Publishers. Shirley Jowell, of Morgan Kaufmann Publishers, and Peter F. Patel-Schneider, of AT&T Bell Laboratories collaborated on their preparation. These instructions can be modified and used in other conferences as long as credit to the authors and supporting agencies is retained, this notice is not changed, and further modification or reuse is not restricted. Neither Shirley Jowell nor Peter F. Patel-Schneider can be listed as contacts for providing assistance without their prior permission. To use for other conferences, change references to files and the conference appropriate and use other authors, contacts, publishers, and organizations. Also change the deadline and address for returning papers and the length and page charge instructions. Put where the files are available in the appropriate places.

The template for BTech Thesis submission for IIT Patna students.
\begin
Discover why over 25 million people worldwide trust Overleaf with their work.